Node.js has a native cluster module to run multiple instances of our application. Node.js uses JavaScript as its language which uses a single thread to handle requests.
Import the cluster module to use Node.js clustering. When the app first starts, check if the process is a master using the cluster.isMaster property from this module. Then call the cluster.fork() method to create multiple child processes.
You can use the os module to find out the number of cores your server has. Create a separate child process for each core.
If you are facing any difficulty understanding so far don't worry. Let me explain what this clustering is all about, how it works, and the importance of using it in your Node.js application.
Also Read: How to Set and Get Cookies in Node.js Express Server
What is Node.js Clustering?
Node.js Clustering is the process of creating child processes (workers) that can handle incoming requests simultaneously. Each process runs an instance of the server.
All the child processes share the same port, event loop, memory, and v8 instance. Node.js has the native cluster module for creating and managing all those instances.
The main or master process distributes the requests among the worker processes to handle. Let's see how it helps to manage more requests.
Importance of Using Node.js Cluster Module
Node.js clustering works like a load balancer. We use this technique to spin up multiple instances of our application. Therefore our server can handle more requests.
We all know Node.js server uses a single thread to execute its code. If you have a CPU with multiple cores, it will not utilize all the resources your system has.
That's why creating and running an instance in each core is also a good way to use the full power of your machine. It also improves performance.
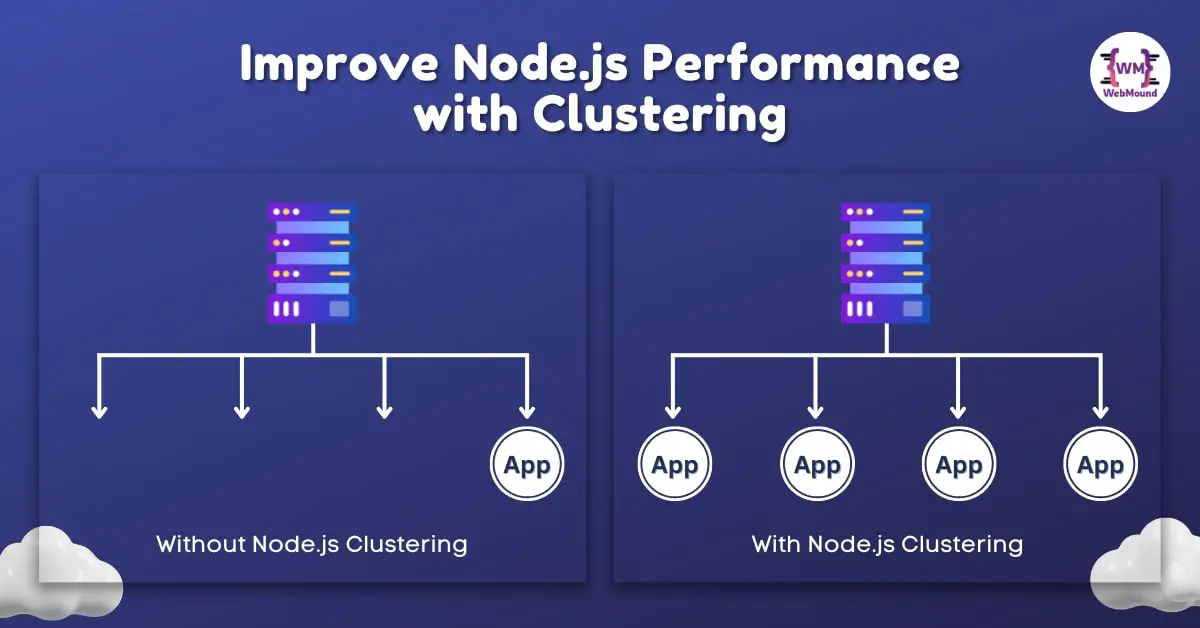
For example, If your machine has a CPU with 4 cores, your Node.js application will use only one core without the clustering. The other 3 cores will remain unused.
But if you are using the cluster module in your application, you can run 4 instances of your application in the 4 cores. Your resources are not being wasted.
Now you are not only utilizing the full power of the machine but your application can handle more requests (almost 4 times) than previous.
It might think this process is very complex but it's not. When we will see the code, everything will be very clear and simple. Because everything is done by Node.js behind the scene for you with just a few lines of code.
Creating an Express Server Without Clustering
To understand the performance difference, I will create 2 versions of my Node.js server. Now I will set up our server without clustering.
I am using Express as the backend framework. This server has 2 simple routes – one for the home page and another will send a JSON response.
If you don't want to use any framework, you can create a server with the HTTP module in NodeJS.
const express = require('express');
const app = express();
app.get('/', function (req, res) {
res.send('Home');
});
app.get('/api/count', (req, res) => {
let count = 0;
for (let i = 0; i < 10000000; i++) {
count += 1;
}
res.json({
success: true,
count,
});
});
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server listening on ${PORT}`);
});
I am using plain JavaScript. But you can set up a Node.js server with Express and TypeScript if you want.
When the /api/count route gets a request, it will run the for loop 10 million times. I am doing it so that this route takes some time before sending the response.
If you set the port number in the environment variable, it will use that. Otherwise, the server will listen to port "3000" as default.
Server listening on 8000
This is how we usually spin up our Node.js server. Now let's apply the clustering to it and then we will test their performance differences.
Adding Node.js Cluster Module to The Express Server
You need to import 2 native modules from NodeJS. You have heard about the cluster module but I will also use the os module to count the number of cores the system has.
When the server first runs, Node.js uses the master process. I am checking if it is a master process using cluster.isMaster property.
const express = require('express');
const os = require('os');
const cluster = require('cluster');
const app = express();
app.get('/', function (req, res) {
res.send('Home');
});
app.get('/api/count', (req, res) => {
let count = 0;
for (let i = 0; i < 10000000; i++) {
count += 1;
}
res.json({
success: true,
count,
id: process.pid,
});
});
if (cluster.isMaster) {
const totalCores = os.cpus().length;
for (let i = 0; i < totalCores; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`);
// Create new worker if one dies
cluster.fork();
console.log('New worker started');
});
} else {
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server ${process.pid} listening on ${PORT}`);
});
}
The code inside the if block will run when the server is in the master process. So, here I am counting the number of cores by accessing the length property after calling cpus() method from the os module.
My computer has 8 CPU cores. It will run the for loop 8 times and call cluster.fork() method to create 8 child processes.
If any worker dies, it will emit the exit event. You can listen to this event and start a new worker by calling the same method. In this way, I can make sure that my server is constantly using 8 child processes.
The code inside the else block will run when it is a child process. That means for 8 child processes, I will have 8 instances of my Node.js server.
Every instance will have the same routes and share the same port number. You can see the ID of each worker from process.pid property.
Server 45124 listening on 3000
Server 45130 listening on 3000
Server 45126 listening on 3000
Server 45129 listening on 3000
Server 45125 listening on 3000
Server 45123 listening on 3000
Server 45127 listening on 3000
Server 45128 listening on 3000
After running the server, you can see that every instance is running on port 3000 but has a different ID number.
Now when the server gets requests, the master process will distribute those requests among the workers. This server now can handle 8 times more requests.
The worker processes use Inter-process communication (IPC) to communicate with the master process.
Also Read: Get Query Strings and Parameters in Express Routes on NodeJS
Performance Difference Between Servers With & Without Clustering
We have created 2 Node.js servers with and without clustering. It's time to see their performance differences. I will use the loadtest package for the testing.
You can install this package globally with the following command:
npm install -g loadtest
We can send any number of requests to our server using this package. I will test our servers one by one.
First I am going to start the server that doesn't use clustering. keep your server running, open a new terminal window and run the following command to perform the test:
loadtest http://localhost:3000/api/count -n 1000 -c 100
This command will send 1000 requests to the /api/count route. It will make 100 requests concurrently.
After executing the above command, let's see the result of the non-clustered server:
Requests: 0 (0%), requests per second: 0, mean latency: 0 ms
Requests: 238 (24%), requests per second: 48, mean latency: 1654.8 ms
Requests: 473 (47%), requests per second: 47, mean latency: 2131.3 ms
Requests: 707 (71%), requests per second: 47, mean latency: 2131.7 ms
Requests: 942 (94%), requests per second: 47, mean latency: 2128.2 ms
Target URL: http://localhost:3000/api/count
Max requests: 1000
Concurrency level: 100
Agent: none
Completed requests: 1000
Total errors: 0
Total time: 21.236817374999998 s
Requests per second: 47
Mean latency: 2016.7 ms
Percentage of the requests served within a certain time
50% 2127 ms
90% 2136 ms
95% 2137 ms
99% 2138 ms
100% 2139 ms (longest request)
If we analyze the result, we will see that it took 21.24 seconds to complete 1000 requests. The server handled on average 47 requests per second. And the mean latency was 2016.7 milliseconds (time taken to complete a single request).
I have tested this server multiple times, and every time I got similar output.
Let's test the other server that uses the clustering. You can use the same command because it is also using the same port number.
loadtest http://localhost:3000/api/count -n 1000 -c 100
It will also send 1000 requests to /api/count route with 100 concurrent requests. Let's see the result:
Requests: 0 (0%), requests per second: 0, mean latency: 0 ms
Target URL: http://localhost:3000/api/count
Max requests: 1000
Concurrency level: 100
Agent: none
Completed requests: 1000
Total errors: 0
Total time: 3.4197234159999996 s
Requests per second: 292
Mean latency: 324.3 ms
Percentage of the requests served within a certain time
50% 343 ms
90% 356 ms
95% 361 ms
99% 384 ms
100% 435 ms (longest request)
We can see this time it took only 3.42 seconds to complete 1000 requests. Every second server handled 292 requests. And mean latency was 324.3 milliseconds.
You can already understand the performance differences between these 2 servers. When the server uses the cluster module, it performs much faster.
This is the summary of our result:
- It took 17.82 seconds less than the previous.
- It handled 245 more requests per second.
- It took 1692.4 milliseconds less to complete a request.
You can see how fast your application will become if you are using Node.js clustering. With this, your server will also use the full power of the machine.
Also Read: How to Rename Multiple Files in a Folder Using Node.js (fs Module)
Conclusion
It is very easy to use the Node.js native cluster module in an application. It not only increases the performance of your app but makes it more efficient as well.
When we run multiple instances of our app, it will reduce downtime. Because if one instance goes down, other instances will handle the requests.
This module can create a new worker process automatically when any process dies. I have shown you how to do it in this article.
Now you can use the Node.js cluster module to improve the server performance for your application with clustering.
